tried importing a csv file with 272 records (as shown by excel and by a delphi routine i "borrowed" and modified). The import resulted in 250 records. Cannot figure out why it is skipping records. the import routing had 7 fields labeled Unknown and I changed them to varchar. I can send you the csv file if you like (has names and addresses from a client so do not want it publicized but nothing really sensitive). thanks.
Problem Importing CSV File
 ansgar posted
11 months ago
ansgar posted
11 months ago
Can you attach that CSV file here?
 John Bell posted
11 months ago
John Bell posted
11 months ago
if you want / need to table, let me know please.
John Bell posted
11 months ago
seems to me attaching that file lets anybody view it which is not quite what i wanted...
ansgar posted
11 months ago
I just deleted your attachment, after downloading it. There is no private area here in the forum.
I could import all 272 rows from that file without issues. I guess you had not checked the "optionally" encloser? Here are my settings for the import:
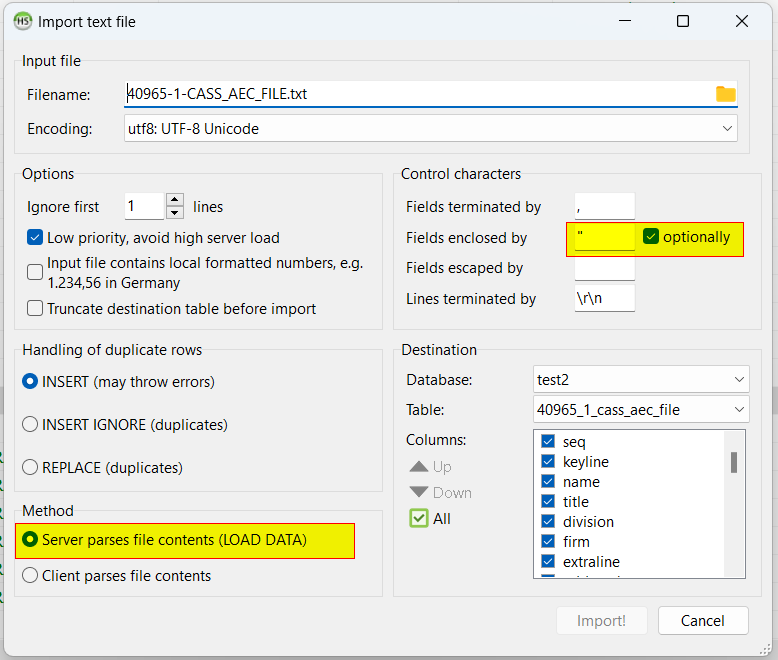
John Bell posted
11 months ago
Ouch! i thought i checked that option. i'm sorry to have wasted your time. ooc, is there any reason to not to check optional? wouldn't it work with a csv file which had all text fields surrounded by quotes as well as one which has only text fields with commas surrounded by quotes. I apologize again (this is sort of embarrassing to say the least.)
 TTSneko posted
11 months ago
TTSneko posted
11 months ago
@John Bell
I had downloaded your file before it went nirvana (I go online via Linux live CD, as soon as I reboot ... poof .. all info gone, no sweat).
Next to what Anse posted please take a look at the CSV file itself in an imported view, best would be in an application like Excel//OpenOffice Calc//whatever that allows a plain CSV import. You will notice that your data is - in itself - inconsistent as not all rows/colums line up, especially in the last third of data. On quick glance that made up for your 'skipped' data.
On another matter: whenever I read CSV and quotes I get hiccups. Most people do not know (or care) that MS Excel has a pretty nasty flaw which will ruin some CSV data if imported/re-exported (ESPECIALLY if fields are a mix of quoted/unquoted entities), meaning that quotes will vanish or 'double up' (creating nonsense like ""test"" or '""test test') which WILL cause you a headache sooner or later. And Excel is only ONE example here.
I am not telling you how to control your workflow but you should really try to avoid such caveats by defining your own CONSISTENT set of rules for importing/exporting all kinds of data. You may also want to check using a semicolon as seperator instead of a comma, as a comma is far too often used in different context, expecially in addresses (think '6, Pearl Harbour Drive' or 'Boston, MA').
John Bell posted
11 months ago
I just loaded the file into excel and it appears that the last field (INFUSE_CASS_ERROR) has values for every entry so i am a little confused. fwiw, i received this data from a mailhouse so have little control over how they format the data. i am perfectly aware of the different "interpretations" of the csv format and have a routine which will import either case. if you would point out which lines in the csv file are inconsistent, i would appreciate it. thanks for looking at this.
TTSneko posted
11 months ago
Sorry, but as I implied your data was dropped when I shut off.
Please login to leave a reply, or register at first.