Hi,
I have just started to use HeidiSQL after mysql query browser and say that simply it is amazing for my needs. I would like to thanks for all people who contributed to this project. My databases are +50 gb.
My question is regarding hanging time at connecting a database . Actually it is because of table status query. As far as I know, at MySql query browser It was not used this statement. I could not find a way to disable this check.
SHOW TABLE STATUS FROM `mydatabase`;
Is there a way to prevent this statements?
Thanks
Preventing long opening time?
 ansgar posted
13 years ago
ansgar posted
13 years ago
You can turn off "Restore last used database at startup" in Tools > Preferences.
![[expired user #5599]'s profile image](http://www.gravatar.com/avatar/8a4488c177d9dc8c3da7c745c89ca214?d=identicon&s=48) [expired user #5599] posted
13 years ago
[expired user #5599] posted
13 years ago
Hi anse,
I know that option but whenever I tried to query my database it is again using "show table status" query at beginning. Because of this, we are waiting more than 4 minutes to connect for querying.
Is this expected behaviour?
My version is 6.0.0.3603
Thanks
I know that option but whenever I tried to query my database it is again using "show table status" query at beginning. Because of this, we are waiting more than 4 minutes to connect for querying.
Is this expected behaviour?
My version is 6.0.0.3603
Thanks
ansgar posted
13 years ago
Well this is how Heidi fetches the objects in your database. There is no way to prevent Heidi from doing that as soon as you go into a database. How does MySQL Query Browser do that?
ansgar posted
13 years ago
I have no such huge db here. You could be so nice and test if firing
takes less time than the above mentioned SHOW TABLE STATUS.
SELECT * FROM information_schema.TABLEStakes less time than the above mentioned SHOW TABLE STATUS.
[expired user #5599] posted
13 years ago
If I understood correctly, Heidi needs this information in order to provide query completetion features. (Please correct me I made a wrong assumtion)
Query browser does not provide such a feature. It does not have code completion feature.
But this query is very expensive for each time when opening/connecting database. Maybe it can be cached? User can force to reload objects.
By the way I am remembering webyoq[1] has such a feature too. But it does not suffer from fetching objects.
[1] http://www.webyog.com/en/
Query browser does not provide such a feature. It does not have code completion feature.
But this query is very expensive for each time when opening/connecting database. Maybe it can be cached? User can force to reload objects.
By the way I am remembering webyoq[1] has such a feature too. But it does not suffer from fetching objects.
[1] http://www.webyog.com/en/
[expired user #5599] posted
13 years ago
My test system:
Mysql 5.1.38
Db: 64,7 gb
/* 0 rows affected, 98 rows found. Duration for 1 query: 271,442 sec. */
/* 0 rows affected, 45 rows found. Duration for 1 query: 199,962 sec. */
Thanks for your attention.
Mysql 5.1.38
Db: 64,7 gb
SELECT * FROM information_schema.TABLES;/* 0 rows affected, 98 rows found. Duration for 1 query: 271,442 sec. */
SHOW TABLE STATUS FROM `mydatabase`;/* 0 rows affected, 45 rows found. Duration for 1 query: 199,962 sec. */
Thanks for your attention.
ansgar posted
13 years ago
> Maybe it can be cached?
They are cached. But of course once loaded and this is obviously your problem. This cached list of tables is used in several other places, not only for code completion. Also you see this list in the tree. So, how does webyog fetch table names if not per SHOW TABLE STATUS, or selecting from information_schema?
As an alternative way to go you should analyze why that takes such a long time on your server. Does sound strange, never heard of that taking so long.
They are cached. But of course once loaded and this is obviously your problem. This cached list of tables is used in several other places, not only for code completion. Also you see this list in the tree. So, how does webyog fetch table names if not per SHOW TABLE STATUS, or selecting from information_schema?
As an alternative way to go you should analyze why that takes such a long time on your server. Does sound strange, never heard of that taking so long.
[expired user #5599] posted
13 years ago
Hi anse,
In order to provide additional data and behviours I have just added a few select queries for you.
/* 0 rows affected, 221 rows found. Duration for 1 query: 0.016 sec. */
/* 0 rows affected, 221 rows found. Duration for 1 query: 20.139 sec. */
/* 0 rows affected, 221 rows found. Duration for 1 query: 21.451 sec. */
I must inform you that our mydatabase is under huge amount insert.
Is it possible to restrict these queries who needs information from database? For example, for many users like me we dont care how much the current size of the tables are.
For furhter information please dont hesitate asking. I will be very glad to support.
Thanks
In order to provide additional data and behviours I have just added a few select queries for you.
SELECT table_schema FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;/* 0 rows affected, 221 rows found. Duration for 1 query: 0.016 sec. */
SELECT * FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;/* 0 rows affected, 221 rows found. Duration for 1 query: 20.139 sec. */
SELECT max_data_length FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;/* 0 rows affected, 221 rows found. Duration for 1 query: 21.451 sec. */
I must inform you that our mydatabase is under huge amount insert.
Is it possible to restrict these queries who needs information from database? For example, for many users like me we dont care how much the current size of the tables are.
For furhter information please dont hesitate asking. I will be very glad to support.
Thanks
ansgar posted
13 years ago
Well that's part of HeidiSQL's architecture, and it's impossible to avoid these queries in some or another way. I'm curious why this query:
SELECT * FROM information_schema.TABLES;
takes 10 times longer than this one:
SELECT * FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;
And why does the first one return only 98 rows while the second one should return less but does return 221 rows? I guess you have tested on different servers which renders the comparison useless now.
SELECT * FROM information_schema.TABLES;
takes 10 times longer than this one:
SELECT * FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;
And why does the first one return only 98 rows while the second one should return less but does return 221 rows? I guess you have tested on different servers which renders the comparison useless now.
[expired user #5599] posted
13 years ago
Sorry for confusion, I was testing at another server that is why counts are different. But both servers are under heavy write. I just wanted to show that maybe some of the fields returned by information_schema are useless.
If It will help you, I can provide all queries what you need to improve this part of the application.
Thanks
ansgar posted
13 years ago
The only question is will be if querying information_schema.tables is faster than SHOW TABLE STATUS. But I guess both need roughly the same time.
Useless for what? HeidiSQL makes use of nearly all fields. However, excluding one or three fields won't make table fetching significantly faster.
I just wanted to show that maybe some of the fields returned by information_schema are useless
Useless for what? HeidiSQL makes use of nearly all fields. However, excluding one or three fields won't make table fetching significantly faster.
[expired user #5599] posted
13 years ago
You are right both of them are almost same in terms of speed... Both of them are almost same.
I would like to ask something. I can see when I right click at the left object/database explorer an option regarding disabling size of the objects.
Maybe if when user click this option, columns at information_schema regarding size at queries could be restricted. Because from my observation I understood that columns regarding size are increasing first time access time to database.
These are some of the fields regarding information schema.
/* 0 rows affected, 221 rows found. Duration for 1 query: 28.595 sec. */
/* 0 rows affected, 221 rows found. Duration for 1 query: 23.931 sec. */
/* 0 rows affected, 221 rows found. Duration for 1 query: 0.015 sec. */
/* 0 rows affected, 221 rows found. Duration for 1 query: 24.788 sec. */
/* 0 rows affected, 221 rows found. Duration for 1 query: 0.015 sec. */
/* 0 rows affected, 221 rows found. Duration for 1 query: 24.555 sec. */
/* 0 rows affected, 221 rows found. Duration for 1 query: 20.170 sec. */
In terms of a developer perspective, code completion features are very important for us. I can sacrifice many things for it but not speed. Since at urgent cases we have to connect database as quickly as possible, such delay sometimes can be fatal for us.
Please forgive my ignorance If I said or will say something wrong. Just tring to make things easier. I really loved this wonderful product.
Thanks
I would like to ask something. I can see when I right click at the left object/database explorer an option regarding disabling size of the objects.
Maybe if when user click this option, columns at information_schema regarding size at queries could be restricted. Because from my observation I understood that columns regarding size are increasing first time access time to database.
These are some of the fields regarding information schema.
SELECT index_length FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;/* 0 rows affected, 221 rows found. Duration for 1 query: 28.595 sec. */
SELECT * FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;/* 0 rows affected, 221 rows found. Duration for 1 query: 23.931 sec. */
SELECT engine FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;/* 0 rows affected, 221 rows found. Duration for 1 query: 0.015 sec. */
SELECT table_rows FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;/* 0 rows affected, 221 rows found. Duration for 1 query: 24.788 sec. */
SELECT version FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;/* 0 rows affected, 221 rows found. Duration for 1 query: 0.015 sec. */
SHOW TABLES FROM `information_schema`;
SELECT * FROM `information_schema`.`SCHEMATA`;
SELECT data_free FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;/* 0 rows affected, 221 rows found. Duration for 1 query: 24.555 sec. */
SELECT avg_row_length FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydatabase' ;/* 0 rows affected, 221 rows found. Duration for 1 query: 20.170 sec. */
In terms of a developer perspective, code completion features are very important for us. I can sacrifice many things for it but not speed. Since at urgent cases we have to connect database as quickly as possible, such delay sometimes can be fatal for us.
Please forgive my ignorance If I said or will say something wrong. Just tring to make things easier. I really loved this wonderful product.
Thanks
 lemon_juice posted
13 years ago
lemon_juice posted
13 years ago
4 minutes wait is extremely long! How many tables do you have in one database?
I also wish Heidi were faster with fetching tables after connecting. Sometimes I have to wait about 10-20 seconds, which seems long to me, 4 minutes would be unbearable... But my databases are much smaller.
Sqlyog is really nice and fast in this respect, I've just had a look and it uses
to fetch the list of tables and it's very fast. Heidi's SHOW TABLE STATUS can be very slow on large databases. The best solution, in my opinion, would for Heidi to use SHOW FULL TABLES like Sqlyog for fetching table list. Of course, this fetches only table names so no other information is available. But in most cases we don't need any more information when there is a need to connect fast and do something. SHOW TABLE STATUS could be run only on demand if the user chooses to fetch more information like table sizes, engine types, etc.
Another thing could be done to enhance speed, much easier I suppose. Heidi runs SHOW TABLE STATUS after each table structure edit after clicking 'Save', which is slow and in 99% of cases unnecessary. I'd be much happier if the table list were refreshed only on demand. How about that?
I also wish Heidi were faster with fetching tables after connecting. Sometimes I have to wait about 10-20 seconds, which seems long to me, 4 minutes would be unbearable... But my databases are much smaller.
Sqlyog is really nice and fast in this respect, I've just had a look and it uses
SHOW FULL TABLES FROM `db` WHERE table_type = 'BASE TABLE';to fetch the list of tables and it's very fast. Heidi's SHOW TABLE STATUS can be very slow on large databases. The best solution, in my opinion, would for Heidi to use SHOW FULL TABLES like Sqlyog for fetching table list. Of course, this fetches only table names so no other information is available. But in most cases we don't need any more information when there is a need to connect fast and do something. SHOW TABLE STATUS could be run only on demand if the user chooses to fetch more information like table sizes, engine types, etc.
Another thing could be done to enhance speed, much easier I suppose. Heidi runs SHOW TABLE STATUS after each table structure edit after clicking 'Save', which is slow and in 99% of cases unnecessary. I'd be much happier if the table list were refreshed only on demand. How about that?
[expired user #5599] posted
13 years ago
Hi lemon_juice,
Our table size not only huge but also under very aggressive writes.
Full tables queries are like this:
/* 0 rows affected, 218 rows found. Duration for 1 query: 5,305 sec. */
/* 0 rows affected, 218 rows found. Duration for 1 query: 0,062 sec. */
/* 0 rows affected, 218 rows found. Duration for 1 query: 0,062 sec. */
Regarding "show table status", I agree with lemon_juice. Maybe we are using different terms in order to express this but "on demand" or "display size object" may be used for this purpose.
But please bear in mind that code complete features are very crucial for us.
Thanks
Our table size not only huge but also under very aggressive writes.
Full tables queries are like this:
SHOW FULL TABLES FROM `mydatabase` WHERE table_type = 'BASE TABLE';/* 0 rows affected, 218 rows found. Duration for 1 query: 5,305 sec. */
SHOW FULL TABLES FROM `mydatabase` WHERE table_type = 'BASE TABLE';/* 0 rows affected, 218 rows found. Duration for 1 query: 0,062 sec. */
SHOW FULL TABLES FROM `mydatabase` WHERE table_type = 'BASE TABLE';/* 0 rows affected, 218 rows found. Duration for 1 query: 0,062 sec. */
Regarding "show table status", I agree with lemon_juice. Maybe we are using different terms in order to express this but "on demand" or "display size object" may be used for this purpose.
But please bear in mind that code complete features are very crucial for us.
Thanks
![[expired user #5421]'s profile image](http://www.gravatar.com/avatar/07dbd9a180c7cc69cada7b982c5ae82c?d=identicon&s=48) [expired user #5421] posted
13 years ago
[expired user #5421] posted
13 years ago
I already have "Restore last used database at startup" turned off.
I have no problem with it if i access stuff that needs that table data,
however there is a typical workflow:
1) connect
2) switch to query tab
3) select db from left pane
4) enter the query and run
5) wait for SHOW TABLE STATUS
6) get the results
I dont see the need for point 5 here really,
also i am able to trick to not wait for it by wrapping query into another like
And for informational purpose:
mydb is 1.5TB / InnoDB tables
I have no problem with it if i access stuff that needs that table data,
however there is a typical workflow:
1) connect
2) switch to query tab
3) select db from left pane
4) enter the query and run
5) wait for SHOW TABLE STATUS
6) get the results
I dont see the need for point 5 here really,
also i am able to trick to not wait for it by wrapping query into another like
select * from (select * from mytable) as mytable)And for informational purpose:
mydb is 1.5TB / InnoDB tables
SELECT * FROM information_schema.TABLES;
/* 0 rows affected, 653 rows found. Duration for 1 query: 134,078 sec. (+ 0,031 sec. network) */
SELECT * FROM INFORMATION_SCHEMA.TABLES where table_schema = 'mydb' ;
/* 0 rows affected, 284 rows found. Duration for 1 query: 31,187 sec. (+ 0,703 sec. network) */
SHOW TABLE STATUS FROM `mydb`;
/* 0 rows affected, 284 rows found. Duration for 1 query: 28,984 sec. */
SHOW FULL TABLES FROM `mydb`;
/* 0 rows affected, 284 rows found. Duration for 1 query: 0,000 sec. */Hi,
I understood why we have very huge amount of time when connecting at the beginning after a few months later. Our very big tables has partitioned tables. We have almost more than 100 tables and each table partitioned to 101.
@anse have you ever tested under such a condition?
What I can suggest is that marshalling this information to file system with an option invalidating it.
I understood why we have very huge amount of time when connecting at the beginning after a few months later. Our very big tables has partitioned tables. We have almost more than 100 tables and each table partitioned to 101.
@anse have you ever tested under such a condition?
What I can suggest is that marshalling this information to file system with an option invalidating it.
ansgar posted
12 years ago
No, I did not test under such condition.
This thread is old and discusses stuff which was already subject to several modifications in HeidiSQL. Please tell me what exactly is slow for you.
This thread is old and discusses stuff which was already subject to several modifications in HeidiSQL. Please tell me what exactly is slow for you.
[expired user #5421] posted
12 years ago
Hi, Ansgar
This is the most irritating thing to date.
It makes you wait 2-3 min after making a connection with HeidiSQL before you can use it on big databases.
Disabling "Restore last used database at startup" just postpones it to just before it starts showing the results of first query.
This is the most irritating thing to date.
It makes you wait 2-3 min after making a connection with HeidiSQL before you can use it on big databases.
Disabling "Restore last used database at startup" just postpones it to just before it starts showing the results of first query.
[expired user #5599] posted
12 years ago
@anse this is the result from our test system
SHOW TABLE STATUS FROM `community`;
/* 0 rows affected, 53 rows found. Duration for 1 query: 173.973 sec. */another information
SELECT * FROM information_schema.TABLES;
/* 0 rows affected, 106 rows found. Duration for 1 query: 251.801 sec. */![[expired user #8907]'s profile image](http://www.gravatar.com/avatar/bac4cbb6173335e862a1b3df635ee3ba?d=identicon&s=48) [expired user #8907] posted
9 years ago
[expired user #8907] posted
9 years ago
Try this...
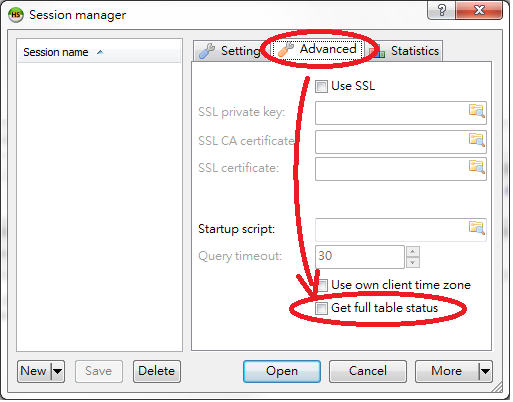
Session Manager > Advanced page
Uncheck Get full table status
Session Manager > Advanced page
Uncheck Get full table status
1 attachment(s):
![[expired user #5392]'s profile image](http://www.gravatar.com/avatar/2a10665525774fa2501c2c8c4985ce61?d=identicon&s=48) [expired user #5392] posted
9 years ago
[expired user #5392] posted
9 years ago
hi data in mysql BIT format is not display HEX and UNHEX
insert data
sql function
hex (n_or_s) cause crash
insert data
sql function
hex (n_or_s) cause crash
[expired user #8907] posted
7 years ago
Hi Try to set global innodb_stats_on_metadata = 0;
refer here dba.stackexchange.com/ questions/39993/show-table-status-very-slow-on-innodb
Please login to leave a reply, or register at first.