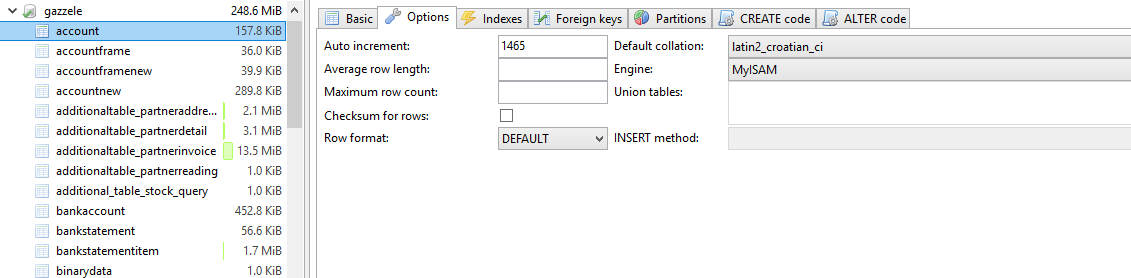
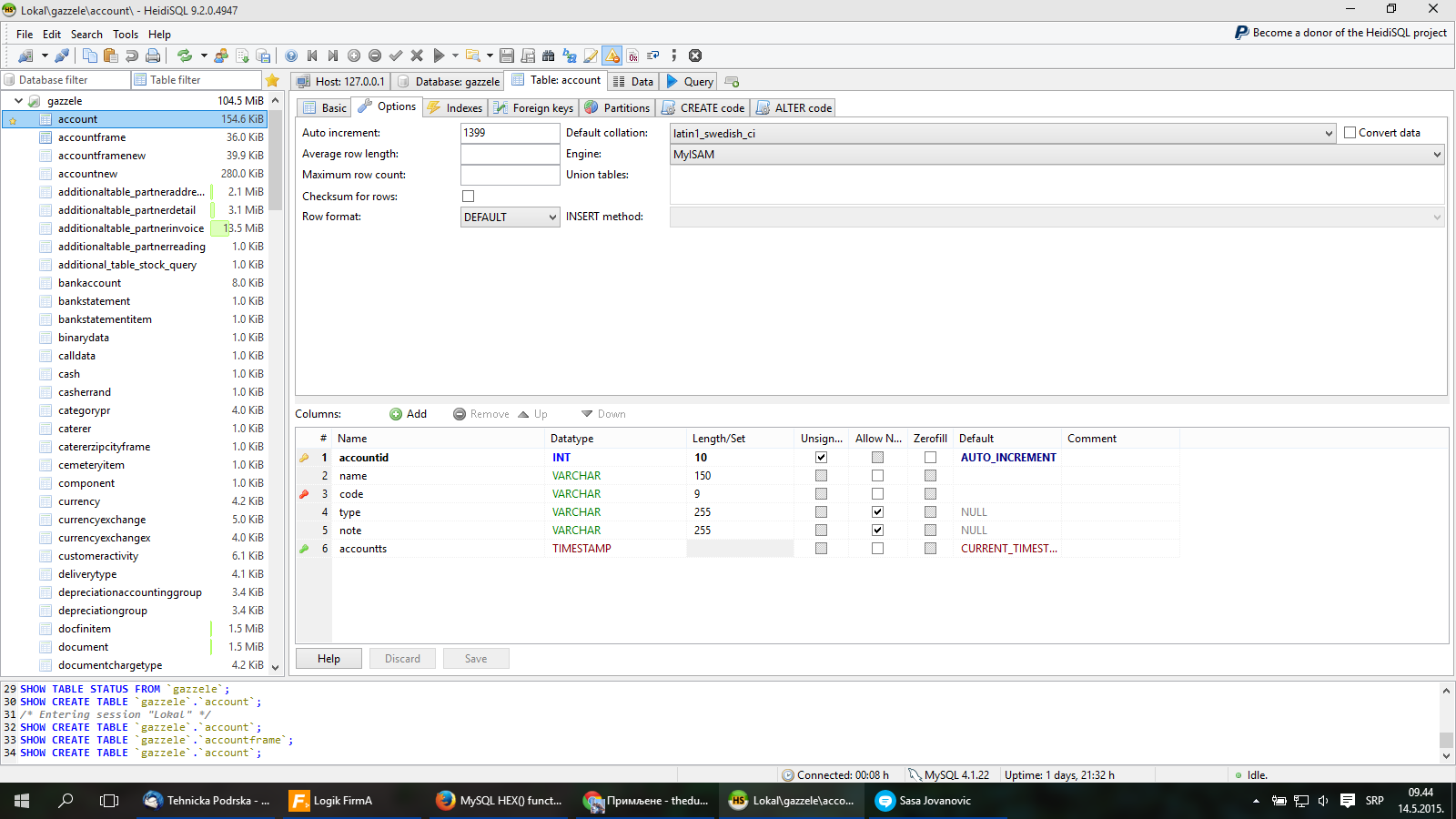
CREATE TABLE `account` (
`accountid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`name` VARCHAR(150) NOT NULL DEFAULT '',
`code` VARCHAR(9) NOT NULL DEFAULT '',
`type` VARCHAR(255) NULL DEFAULT NULL,
`note` VARCHAR(255) NULL DEFAULT NULL,
`accountts` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`accountid`),
UNIQUE INDEX `code` (`code`),
INDEX `accountts` (`accountts`)
)
COLLATE='latin1_swedish_ci'
ENGINE=MyISAM
AUTO_INCREMENT=1465
;
Collation is "latin1_swedish".
At the time the database was created close to 2000 there was no other option and everything work perfectly.
But again Heidi version 5 all operate normally.
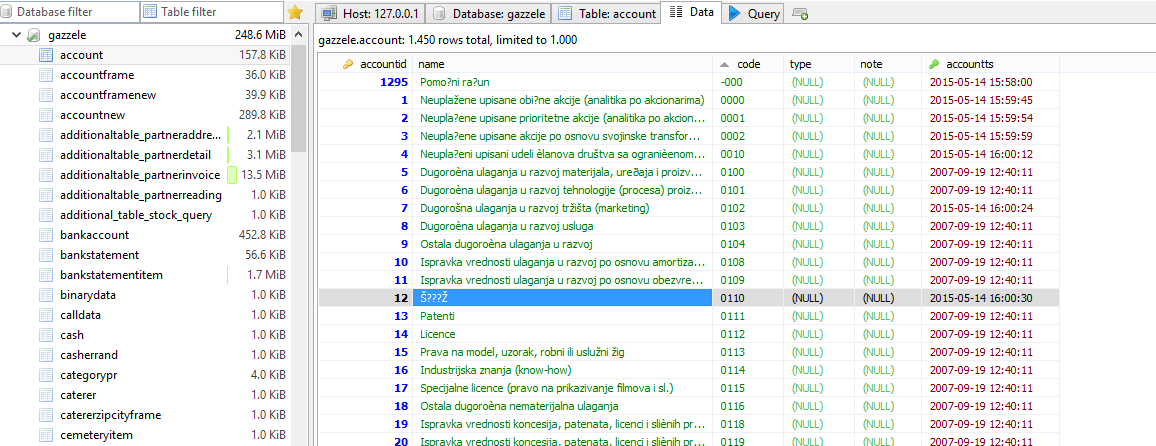
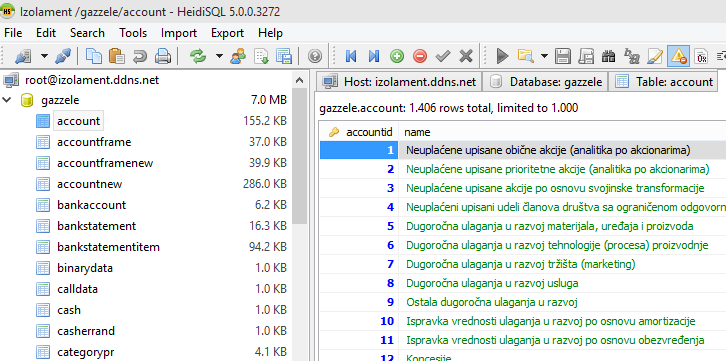
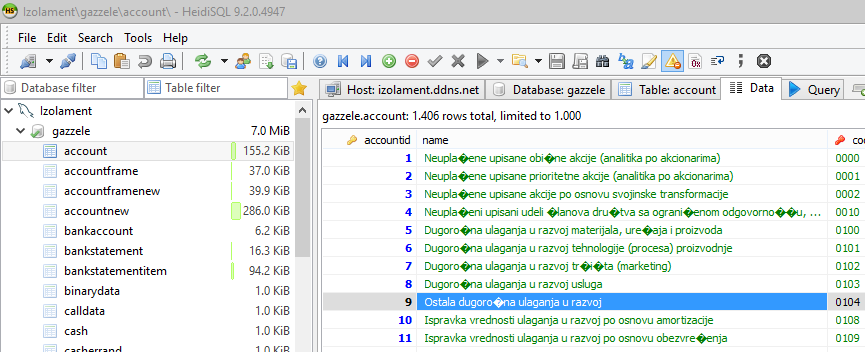
When I set a colation to latin2_croatian_ci, instead of Serbian letters I again receive various sings.
Picture is in Attach.
![[expired user #8926]'s profile image](http://www.gravatar.com/avatar/82b04cd5aa016d979fe048f3ddf0e8d3?d=identicon&s=100) [expired user #8926] posted
[expired user #8926] posted
 kalvaro posted
kalvaro posted
 ansgar posted
ansgar posted